








Breaking News
 No, The Spanish Invaders Have Not All Just 'Gone Home'
No, The Spanish Invaders Have Not All Just 'Gone Home'
 From Influence Peddler To Starving Artist: Hunter Biden Claims Family Is Broke In Defaulting...
From Influence Peddler To Starving Artist: Hunter Biden Claims Family Is Broke In Defaulting...
 'Defend Israel Or The Homeland': Top US General Issues Stark Warning To Pentagon Brass
'Defend Israel Or The Homeland': Top US General Issues Stark Warning To Pentagon Brass
 The Summer Slump in the Vegetable Garden (How We Survive!)
The Summer Slump in the Vegetable Garden (How We Survive!)
Top Tech News
 Idaho's High Desert Becomes Hot Spot For Nuclear Power Revolution
Idaho's High Desert Becomes Hot Spot For Nuclear Power Revolution
 The World's Largest Electric Aircraft Is About to Take Its First Flight
The World's Largest Electric Aircraft Is About to Take Its First Flight
 Tesla Cybercabs and Superchargers Will Act as Mini Cell Towers for SpaceX Starlink
Tesla Cybercabs and Superchargers Will Act as Mini Cell Towers for SpaceX Starlink
 Elon Vows AI-Made 'Odyssey' After Blasting Nolan's Take On Homer
Elon Vows AI-Made 'Odyssey' After Blasting Nolan's Take On Homer
 Anthropic is launching its own drug discovery programs for rare diseases using Claude...
Anthropic is launching its own drug discovery programs for rare diseases using Claude...
 SpaceX AI Satellites Will Have 250 Kilowatts of Power
SpaceX AI Satellites Will Have 250 Kilowatts of Power
 Chinese researchers have developed a sodium-metal battery that can fully charge in just 4 minutes...
Chinese researchers have developed a sodium-metal battery that can fully charge in just 4 minutes...
 SpaceX Starship Flight 13 in 3 Days - Thursday July 13
SpaceX Starship Flight 13 in 3 Days - Thursday July 13
 Chinese Scientists Develop Nuclear Battery Using Carbon-14
Chinese Scientists Develop Nuclear Battery Using Carbon-14
 Teleoperated humanoid robots complete first-ever live surgery
Teleoperated humanoid robots complete first-ever live surgery



Three Eras of Machine Learning and Predicting the Future of AI
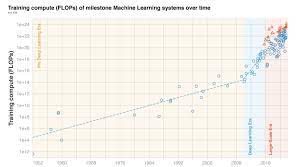
They show :
before 2010 training compute grew in line with Moore's law, doubling roughly every 20 months.
Deep Learning started in the early 2010s and the scaling of training compute has accelerated, doubling approximately every 6 months.
In late 2015, a new trend emerged as firms developed large-scale ML models with 10 to 100-fold larger requirements in training compute.
Based on these observations they split the history of compute in ML into three eras: the Pre Deep Learning Era, the Deep Learning Era and the Large-Scale Era . Overall, the work highlights the fast-growing compute requirements for training advanced ML systems.
They have detailed investigation into the compute demand of milestone ML models over time. They make the following contributions:
1. They curate a dataset of 123 milestone Machine Learning systems, annotated with the compute it took to train them.