Breaking News
 If You Want to MAHA, Plant a Garden
If You Want to MAHA, Plant a Garden
 Iran's PressTV provides a different account of the War than Trump
Iran's PressTV provides a different account of the War than Trump
 For peace with Iran to work a reckoning with Israel is in order
For peace with Iran to work a reckoning with Israel is in order
 SpaceX Revenue Will Be Close to Around $27-30 Billion in 2026
SpaceX Revenue Will Be Close to Around $27-30 Billion in 2026
Top Tech News
 'World's First' Humanoid Robot For Real Household Chores Launched With 16-Hour Battery
'World's First' Humanoid Robot For Real Household Chores Launched With 16-Hour Battery
 XAI Training 10 Trillion Parameter Model – Likely Out in Mid 2026
XAI Training 10 Trillion Parameter Model – Likely Out in Mid 2026
 The $7 Powder That Beats Your $5,000 AC Unit!
The $7 Powder That Beats Your $5,000 AC Unit!
 Private credit is now a $3 trillion asset class and investors are receiving 45 cents on the dollar
Private credit is now a $3 trillion asset class and investors are receiving 45 cents on the dollar
 Converting Diesel Vehicles to Run on Waste Vegetable Oil, by Polar Bear
Converting Diesel Vehicles to Run on Waste Vegetable Oil, by Polar Bear
 Anthropic says its latest AI model is too powerful for public release and that it broke...
Anthropic says its latest AI model is too powerful for public release and that it broke...
 The CIA used a futuristic new tool called "Ghost Murmur" to find and rescue...
The CIA used a futuristic new tool called "Ghost Murmur" to find and rescue...
 This Plant Replaces All Fertilizer FOREVER. Why Did the FDA Ban It?
This Plant Replaces All Fertilizer FOREVER. Why Did the FDA Ban It?
 China Introduces Pistol-Like Coil-Gun Based On Electromagnetic-Launch Systems
China Introduces Pistol-Like Coil-Gun Based On Electromagnetic-Launch Systems
 NEXT STOP: MARS IN JUST 30 DAYS?!
NEXT STOP: MARS IN JUST 30 DAYS?!


XAI Training 10 Trillion Parameter Model – Likely Out in Mid 2026

Grok Imagine V2
2 variants of 1-trillion-parameter models
2 variants of 1.5-trillion-parameter models
1 variant of a 6-trillion-parameter model
1 variant of a 10-trillion-parameter model
xAI would be leading in raw announced scale of parameters. No other lab has publicly confirmed training 10T or even 6T models right now. The 6T model alone is roughly double the rumored size of Grok 4 and far larger than most current estimates for GPT-5 or Claude 4.6.
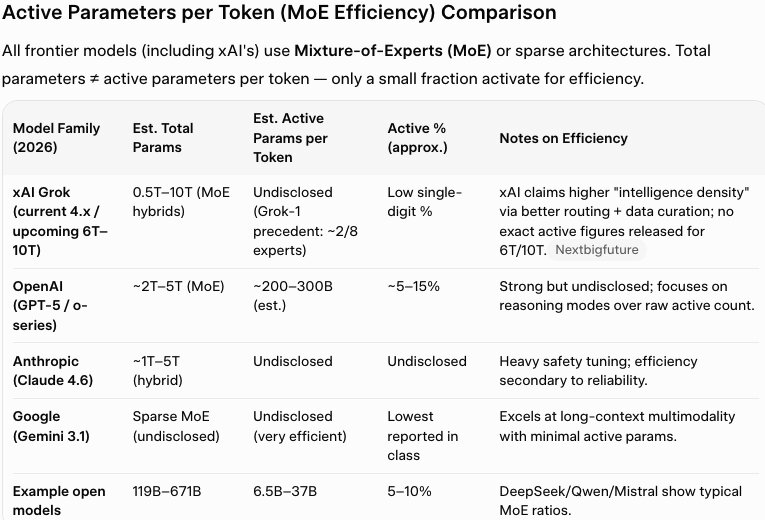
Parameter count is only part of the story.
AI models are judged more on:
Active parameters per token (MoE efficiency).
Training data quality and "intelligence density" (xAI claims higher density per gigabyte).
Inference-time compute (reasoning modes, multi-agent orchestration).
Real-world benchmarks (coding, agentic tasks, multimodality).
Chips Needed & Costs for Pre-Training Runs
Exact per-model costs are not public (models are still training), but here are the best analyses and estimates.
Colossus 2 hardware: ~550,000 NVIDIA GPUs (mostly GB200/GB300 Blackwell variants) at ~$18 billion hardware cost alone (average ~$32k–$40k per GPU). This supports the full parallel training lineup.
Total CapEx is tens of billions of dollars for Colossus 2 (land, power infrastructure, cooling, networking). Includes on-site gas turbines/Megapacks for 400+ MW dedicated power and rapid buildout.
Per-model rough estimates (community/analyst extrapolations).
10T model needs ~$1.5 billion+ in compute (one early analyst call. scales with FLOPs and duration). Initial pre-training phase ~2 months on Colossus 2.
6T model needs Similar order of magnitude but lower. benefits from shared cluster efficiency.
Smaller 1T/1.5T runs: Significantly cheaper/faster due to parallelization.