








Breaking News
 We're Already Living in an Alien Invasion Movie
We're Already Living in an Alien Invasion Movie
 BBC Hands Soros-Linked Pro-Migrant Campaigners Direct Access To Shape Children's Show
BBC Hands Soros-Linked Pro-Migrant Campaigners Direct Access To Shape Children's Show
 Telegram Founder Warns UK Social Media Ban Is Digital Iceberg About To Sink The Free Internet
Telegram Founder Warns UK Social Media Ban Is Digital Iceberg About To Sink The Free Internet
 No FISA Without SAVE Act: Trump Calls Out 'Dumocrat' Double-Cross," Keeps Pulte As Acti
No FISA Without SAVE Act: Trump Calls Out 'Dumocrat' Double-Cross," Keeps Pulte As Acti
Top Tech News
 Heads up: Apparently the government is hiding cameras inside fake utility boxes
Heads up: Apparently the government is hiding cameras inside fake utility boxes
 Sodium Batteries And EVs That Power The Grid: Inside GM's Big Energy Push
Sodium Batteries And EVs That Power The Grid: Inside GM's Big Energy Push
 NUCLEAR ENGINE - UNLIMITED LUXURY - 20 YEARS WITHOUT REFUELING
NUCLEAR ENGINE - UNLIMITED LUXURY - 20 YEARS WITHOUT REFUELING
 China Unveils Nuclear-Powered Floating Hub For Green Shipping
China Unveils Nuclear-Powered Floating Hub For Green Shipping
 China Launches World's 1st Commercial Brain Chip, Beating Elon Musk's Neuralink!
China Launches World's 1st Commercial Brain Chip, Beating Elon Musk's Neuralink!
 Modular next-gen US nuclear reactor goes critical
Modular next-gen US nuclear reactor goes critical
 How EMF's cause disease
How EMF's cause disease This Company Will Add Phone, AirPod, and Smartwatch Trackers to License Plate Readers
This Company Will Add Phone, AirPod, and Smartwatch Trackers to License Plate Readers
 Elon Details SpaceX AI Data Center in Space Details and Roadmap
Elon Details SpaceX AI Data Center in Space Details and Roadmap
 5-in-1 miniature surgical robot is the size of a seed
5-in-1 miniature surgical robot is the size of a seed 


AI voice cloning from a few seconds of voice sampling is real and rapidly improving
There are examples of speech sample recordings and synthesized speech based on different numbers of samples. The synthesized speech had some noise distortion but the samples did sound like the original speakers.
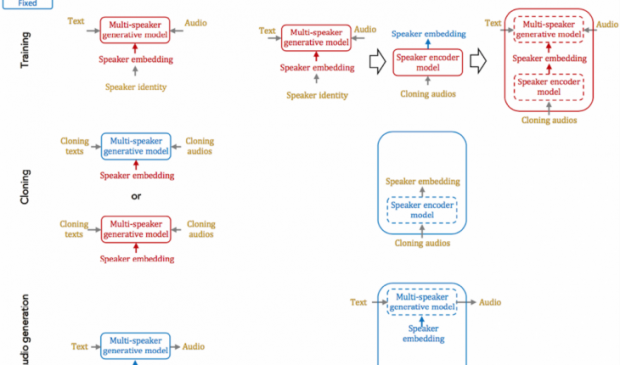
Baidu attempted to learn speaker characteristics from only a few utterances (i.e., sentences of few seconds duration). This problem is commonly known as "voice cloning." Voice cloning is expected to have significant applications in the direction of personalization in human-machine interfaces.
They tried two fundamental approaches for solving the problems with voice cloning: speaker adaptation and speaker encoding.
Speaker adaptation is based on fine-tuning a multi-speaker generative model with a few cloning samples, by using backpropagation-based optimization. Adaptation can be applied to the whole model, or only the low-dimensional speaker embeddings. The latter enables a much lower number of parameters to represent each speaker, albeit it yields a longer cloning time and lower audio quality.